Ambiguity Problems and Eliminating the Ambiguity

Understanding Ambiguity in Compilers
Ambiguity in compilers can lead to significant problems. It occurs when the meaning of a program can be incorrect due to the lack of precision in the language syntax. One classic example of such ambiguity is the "dangling else" problem.
Dangling Else Problem
Consider the following statement:
if E1 then if E2 then S1 else S2
Here, E1, E2, S1, and S2 represent any expressions or statements. The dangling else problem arises because it's unclear to which if statement the else clause should be attached.
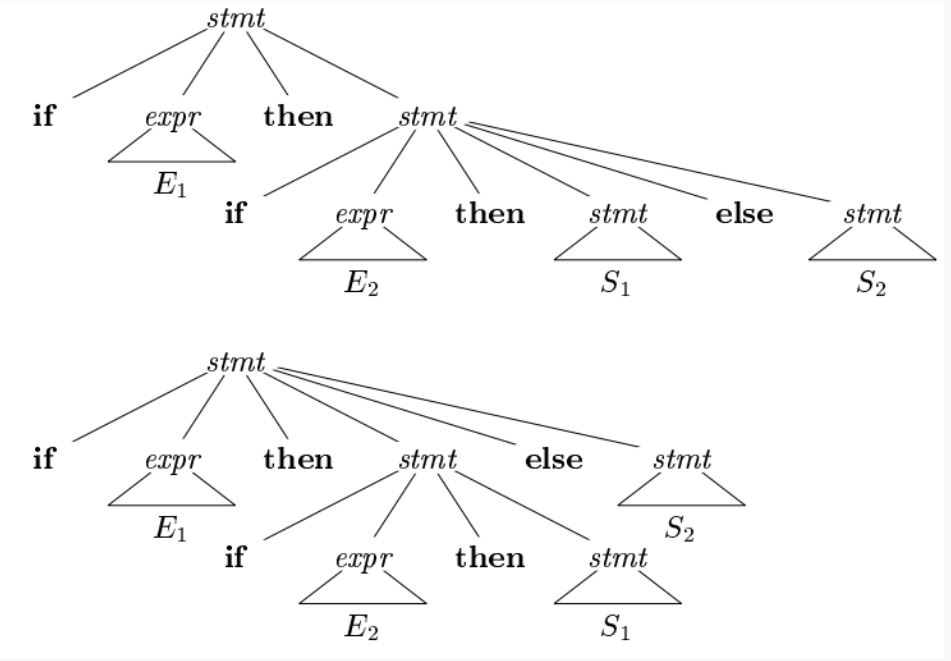
Example
Let's consider the following values: E1 = false, E2 = true, S1 = z := 10, and S2 = z := 0.
- If we parse this statement using the top tree, the
zvariable doesn't get set, which is incorrect. - If we parse using the bottom tree,
z = 0, which is also incorrect.
Both trees are valid parse trees for the given statement, leading to ambiguity.
Resolving Ambiguity
To resolve this ambiguity, we can use braces {} and indentation to clearly indicate the structure of the if statements. For example:
if E1 {
if E2 {
S1
} else {
S2
}
}
In this case, it's clear that the else clause belongs to the inner if statement.
Another solution is to use the if-else if-else format, which specifically indicates which else belongs to which if.
Note: In practice, if there is no clear way to resolve the ambiguity, compilers usually associate the else with the nearest if.
stmt -> matched_stmt
| open_stmt
matched_stmt -> if expr then matched_stmt else mathed_stmt
| other
open_stmt -> if expr then stmt
| if expr then matched_stmt else open_stmt
Parsing reminder
Parsing, also known as syntax analysis, is a critical phase in the process of compiling or interpreting a programming language. It's the process of determining whether a string of terminals can be generated by a grammar. In simpler terms, parsing is the task of checking if a given sequence of tokens (the output from the lexical analysis phase) conforms to the syntactic rules of a programming language. A parser is a program that performs this syntax analysis. It takes as input the tokens from the lexical analyzer (the previous phase of the compilation process) and treats the token names as terminal symbols of a context-free grammar. The parser's main job is to construct a parse tree, which is a hierarchical representation of the source code that reflects the grammatical structure of the program.
The parse tree can be constructed in two ways:
-
Guratively: This involves going through the corresponding derivation steps. It starts from the start symbol of the grammar and applies the production rules in a top-down manner to generate the parse tree.
-
Literally: This involves constructing the parse tree directly from the input string. It starts from the leaves of the parse tree and applies the production rules in a bottom-up manner to generate the parse tree
There are several types of parsing algorithms used in syntax analysis, including LL parsing, LR parsing, LR(1) parsing, and LALR parsing. Each of these algorithms has its own strengths and weaknesses, and the choice of algorithm depends on the specific requirements of the programming language being compiled or interpreted. Parsing is an essential step in the compilation process because it allows the compiler to check if the source code follows the grammatical rules of the programming language. This helps to detect and report errors in the source code, and it also enables the compiler to generate more efficient and optimized code.
For example:
For this sentence:
She loves animals $\rightarrow$ Parser $\rightarrow$
Sentence
/ | \
/ | \
/ | \
pornoun verb noun
| | |
She loves animals
Types of Parsing
Syntax analyzers follow production rules defined by means of context-free grammar. The way the production rules are implemented (derivation) divides parsing into two types : top-down parsing and bottom-up parsing.
Top-down Parsing
When the parser starts constructing the parse tree from the start symbol and then tries to transform the start symbol to the input, it is called top-down parsing.
Recursive descent parsing : It is a common form of top-down parsing. It is called recursive as it uses recursive procedures to process the input. Recursive descent parsing suffers from backtracking.
Backtracking : It means, if one derivation of a production fails, the syntax analyzer restarts the process using different rules of same production. This technique may process the input string more than once to determine the right production.
Bottom-up Parsing
As the name suggests, bottom-up parsing starts with the input symbols and tries to construct the parse tree up to the start symbol.
Example: Input string : a + b * c
Production rules:
S → E
E → E + T
E → E * T
E → T
T → id
Let us start bottom-up parsing
a + b * c
Read the input and check if any production matches with the input:
a + b * c
T + b * c
E + b * c
E + T * c
E * c
E * T
E
S